
(This blog entry was brought back in order to resolve a frequent source of 404 log entries.)
The Adjustable Replacement Cache (ARC) of Solaris ZFS
The Adjustable Replacement Cache (ARC) of Solaris ZFS is a really interesting piece of software. Interestingly, it’s based on a development by IBM — the Adaptive Replacement Cache as described by Megiddo and Modha — but the developers of ZFS extended it for their own purposes. The original implementation was presented at FAST 2003 and described in this article in ;login:.
It’s a truly elegant design. In the following description I’ve simplified some mechanisms to make things easier to understand. The authoritative source of information about the ARC in ZFS is http://src.opensolaris.org/source/xref/onnv/onnv-gate/usr/src/uts/common/fs/zfs/arc.c. In the next paragraphs I will try to give you some insight into the inner workings of the read cache of ZFS. I will concentrate on how data gets into the cache and how the cache adjusts itself to the workload, thus earning its moniker “Adjustable Replacement Cache”.
Caches
The standard LRU mechanisms of other file system caches have some shortfalls. For example, they are not scan-resistant. When you read a large number of blocks sequentially, they tend to fill up the cache, even when they are read just once. When the cache is full and you want to place new data in it, the least recently used page is evicted from the cache (thrown out of it). In the case of such large sequential reads, the cache would contain only those reads and not the actually frequently used data. When the large sequential reads are only used once, the cache is filled with worthless data from the perspective of caching.
There is another challenge: A cache can optimise for recency (by caching the most recently used pages) or for frequency (by caching the most frequently used pages). Neither approach is optimal for every workload. Thus a good cache design needs to be able to optimise itself.
The inner workings of ARC
The ARC solves these challenges both in its original implementation and in the extended implementation in ZFS. I will describe the fundamental concept of the Adaptive Replacement Cache as described by Megiddo and Modha, as the additional mechanisms of the ZFS implementation somewhat obscure the simplicity and effectiveness of the underlying mechanism. Both implementations (the original Adaptive Replacement Cache and the ZFS Adjustable Replacement Cache) share their basic theory of operation, so I think this simplification is a viable way to explain ZFS ARC.
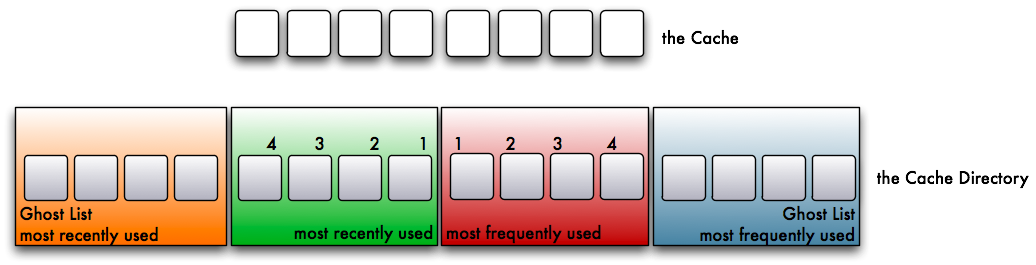
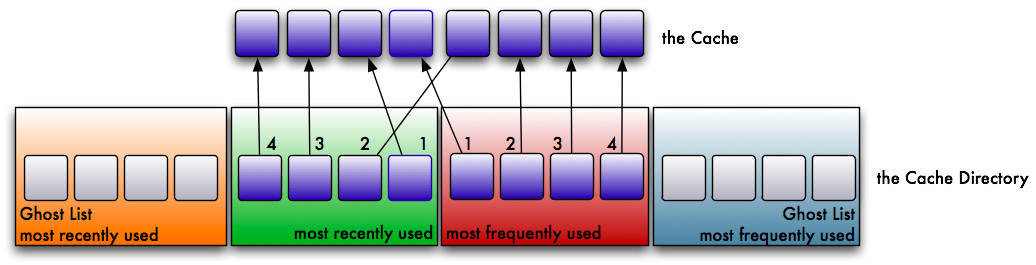
Let’s assume that you have a certain number of pages in your cache. For simplicity, we will assume a cache sized for 8 pages. For its operation, the ARC needs a directory table twice the size of the cache.
This table is separated into 4 lists. The first two are the obvious ones:
- a list for the most recently used pages
- a list for the most frequently used pages
The other two are a little stranger in their role. They are called ghost lists. They are filled with recently evicted pages from both lists:
- a list for the recently evicted pages from the most recently used list
- a list for the recently evicted pages from the most frequently used list
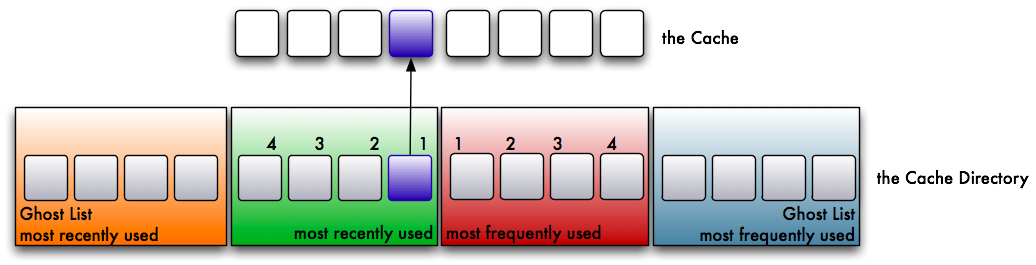
The ghost lists don’t cache data, but a hit on them has an important effect on the behaviour of the cache, as I will explain later. So what happens in the cache? Let’s assume we read a page from disk. We place it in the cache. The page is referenced in the recently used list.
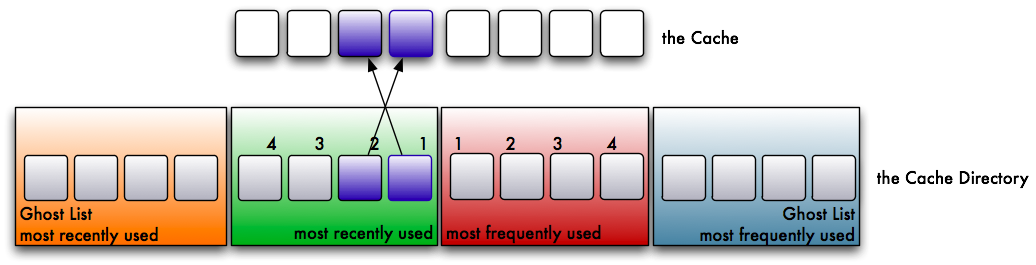
We read another, different page. It’s placed in the cache as well and put into the recently used list at the most recently used position (position 1).
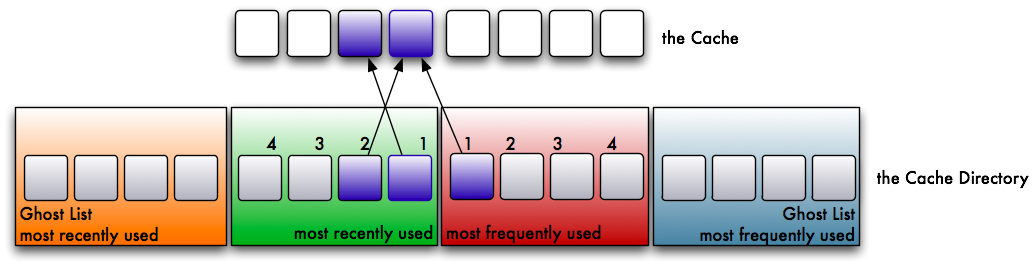
Now we read the first page again. This time the reference is moved over to the frequently used list. A page has to be used at least twice to get into this list. Whenever a page on the frequently used list is accessed again, it is moved back to the beginning of the list. By doing so, truly frequently accessed pages stay in cache, while less frequently accessed pages wander to the end of the list and eventually get evicted.
Over time both lists fill up and the cache is filled accordingly. But then one of the cache areas is full and you read an uncached page. One page has to be evicted from the cache to make room for the new one. Pages can only be evicted from cache when they are not referenced by any of the non-ghost lists.
Let’s assume that the list for recently used pages is now full:
The cache evicts the least recently used page. This page is put onto the ghost list of recently evicted pages.
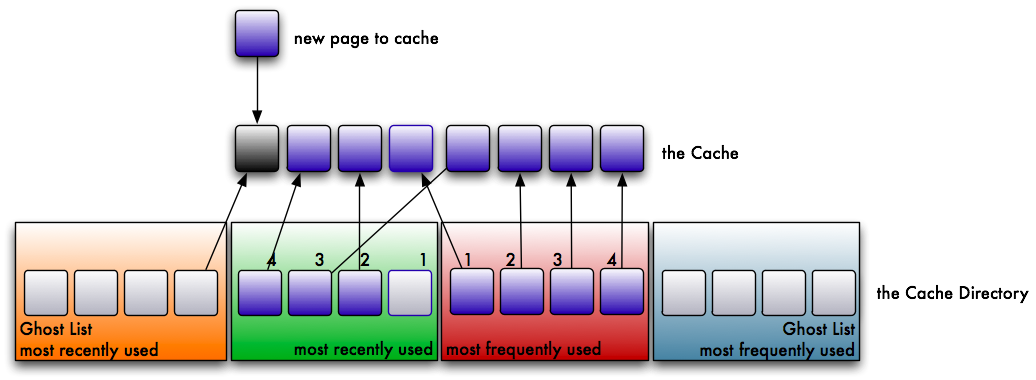
Now the page in the cache is no longer referenced and can be evicted. The new page gets referenced by the cache directory instead.
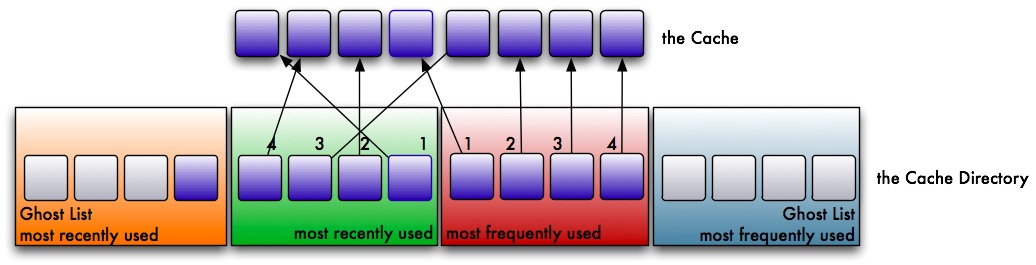
With every further eviction, this entry wanders towards the end of the ghost list. At a later point in time the reference reaches the end of the list, and after the next eviction it is removed entirely — there is no reference in any list anymore.
But what happens when we read a page that is on the ghost list of already evicted pages? Such a read leads to a phantom cache hit. Since the actual data has already been evicted from cache, the system has to read it from the storage medium. However, through this phantom hit the system knows that this was a recently evicted page — not a page read for the first time or one read a long time ago. The ARC can use this information to adjust itself to the workload.
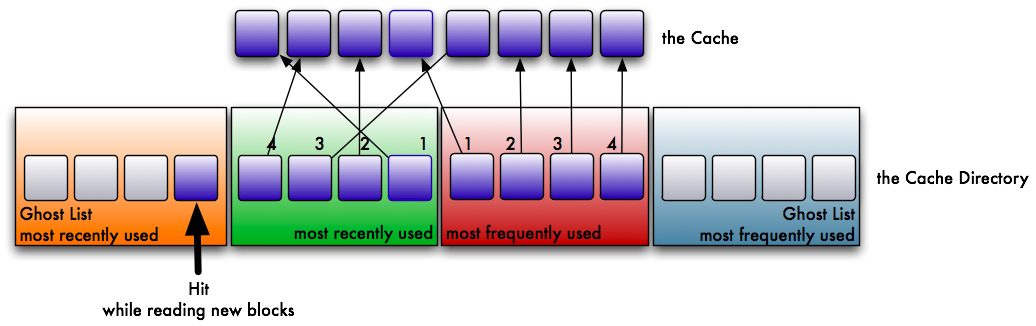
This is a sign that the recently used portion of our cache is too small. In response, the maximum length of the recently used list is increased by one — which in turn reduces the space for frequently used pages by one.
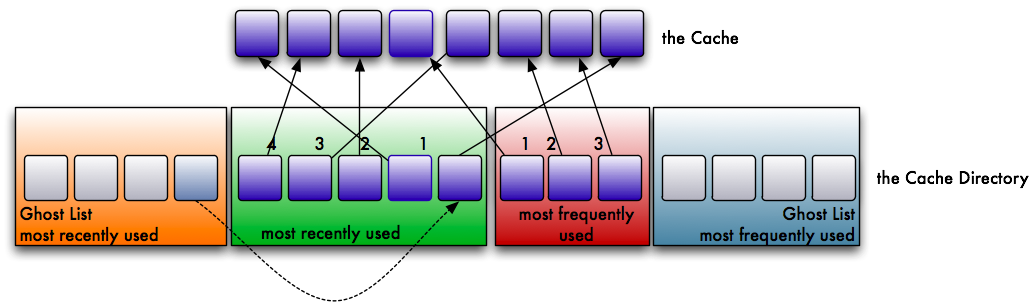
The same mechanism works on the other side as well. If you get a hit on the ghost list for frequently used pages, it decreases the recently used list by one, which increases the available space for frequently used pages by one.
Through this behaviour the ARC adapts itself to the workload. If the workload favours recently accessed files, there will be more hits in the ghost list for recently used pages, and thus the cache will grow that portion. Conversely, if the workload favours frequently accessed files, there will be more hits on the ghost list for frequently used pages, and the cache will grow in favour of those.
Furthermore, this enables a neat feature: Let’s assume you read through a large number of files for log file processing. You need every page only once. A normal LRU-based cache would load all these pages into the cache, evicting all frequently accessed pages in the process. But since you access them only once, they just fill up the cache without bringing any advantage.
A cache based on ARC behaves differently. Such a workload would start to fill up the recently used portion of the cache very quickly, and pages get evicted soon. But since each of these pages is accessed only once, it is highly improbable that they will produce hits in the ghost list for recently used pages. Thus the recently used portion of the cache doesn’t grow due to these single-access pages.
Now let’s assume you correlate the data in the log files with a large database (for simplification we assume it doesn’t have its own caching mechanism). It accesses pages in the database files quite frequently. The probability of accessing pages referenced in the ghost list for frequently used pages is much higher than in the ghost list for recently used pages. Thus the cache for frequently accessed database pages would grow. In essence, the cache optimises itself for the database pages instead of being polluted with log file pages.
The modified Solaris ZFS ARC
As I wrote before, the implementation in ZFS isn’t the pure ARC as described by the two IBM researchers. It was extended in several ways:
- The ZFS ARC is variable in size and can react to the available memory. It can grow when memory is available or shrink when memory is needed for other purposes.
- The ZFS ARC can work with multiple block sizes. The original implementation assumes an equal size for every block.
- You can lock pages in the cache to exempt them from eviction. This prevents the cache from evicting pages that are currently in use. The original implementation doesn’t have this feature, so the algorithm to choose pages for eviction is slightly more complex in the ZFS ARC. It chooses the oldest evictable page for eviction.
There are some other changes, but I will leave those for the reader to discover in the well-commented source code of arc.c.
The L2ARC
The L2ARC keeps the model described in the paragraphs above untouched. The ARC doesn’t automatically move pages to the L2ARC instead of evicting them. Although this would seem the logical approach, it would have severe consequences. First, a sequential read burst would overwrite large portions of the L2ARC, as such a burst would evict many pages in a short period. This is undesirable.
The second problem: Let’s assume your application needs a large heap of memory. The modified Solaris ARC is able to resize itself according to available memory. When applications request more memory, the ARC has to shrink. You have to evict a large number of memory pages at once. If every page were written to the L2ARC before eviction from ARC, this would add substantial latency before your system can provide more memory, as it would have to wait for the L2ARC writes to complete.
The L2ARC mechanism tackles this problem differently: There is a thread called l2arc_feed_thread that walks over the soon-to-be-evicted ends of both lists — the recently used list and the frequently used list — and puts them into a buffer (8 MB). From there, another thread (the write_hand) writes them to the L2ARC in a single write operation.
This algorithm has many advantages: The latency of freeing memory is not increased by the eviction. In a mass-eviction scenario caused by a sequential read burst, the blocks are evicted before the l2arc_feed_thread traverses the ends of the lists. So the effect of polluting the L2ARC by such read bursts is reduced (albeit not completely eliminated).
Conclusion
The design of the Adjustable Replacement Cache is much more efficient than ordinary LRU cache designs. Megiddo and Modha were able to demonstrate much better hit rates with their original Adaptive Replacement Cache (a comparison is included at the end of the ;login: article). The ZFS ARC shares the same basic theory of operation, so the hit rate advantages should be similar. More importantly, the idea of using large SSD-based caches becomes even more viable when the cache algorithm helps achieve an even better hit rate.
Want to learn more?
- The theory of ARC operation in One Up on LRU, written by Megiddo and Modha, IBM Almaden Research Center.
- The implementation in ZFS is described in the source code. The file
arc.ccontains many comments. So use the source, Luke.
{kind=link}